
Reading the news with Newsboat and Lynx
I like to read the news, but I don’t like being bombarded with autoplaying videos, popups, or other distracting elements. Additionally, I would like to use tools that help me parse through articles quicker if I want, like I did with YouTube videos. Because of this, I want to read news on the command line in plain text.
To point us in the right direction, let’s take a look at file format that is well suited for reading news: RSS feeds.
RSS
RSS feeds are files that contain data which tells software what content is available to read, and where to read it. RSS files are usually accessed via a URL. This URL is what connects an RSS reader to its news source.
A sample RSS file
Here’s a sample of what an RSS file looks like. I’ve omitted some parts for brevity.
<rss xmlns:atom="http://www.w3.org/2005/Atom" version="2.0">
<channel>
<title>NASA Space Station News</title>
<link>http://www.nasa.gov/</link>
<description>A RSS news feed containing the latest NASA press releases on the International Space Station.</description>
<!-- ... -->
<item>
<title>Louisiana Students to Hear from NASA Astronauts Aboard Space Station</title>
<link>http://www.nasa.gov/press-release/louisiana-students-to-hear-from-nasa-astronauts-aboard-space-station</link>
<description>As part of the state's first Earth-to-space call, students from Louisiana will have an opportunity soon to hear from NASA astronauts aboard the International Space Station.</description>
<!-- ... --->
</item>
<!-- more items here... -->
</channel>
</rss>
Notice how the RSS file contains relevant information such as:
- Where the feed is coming from. You can see this in the
<link>elements. - Details about the feed and its articles. These can be found in the
<description>elements. - A list of the articles within this feed. Each
<item>element represents an article from this feed.
With this information, an RSS reader can show a news source, their articles, and provide a way to access an individual article. Since the source of the feed is also present (in this case, http://www.nasa.gov/), an RSS feeder knows where to request updates to a news source’s articles, allowing them to stay updated with the latest stories.
However, finding the right URL for a news source can be a challenge. Some sites have clear links that point you to the feed. Others do not.
Finding RSS feeds
Fortunately I found RSS Lookup, a tool built by Max Ratmeyer. This can help find an RSS feed with a news source’s URL. However, if you find this tool’s human verification annoying, you can find the correct link yourself by following these steps:
- Open the page you’re looking for in a web browser.
You may want a more specific list of articles, which can be found in a “categories” or “tags” page, like this one.
- Open the page’s source.
This’ll be different depending on your browser, but for Chrome based browsers, you can use the Ctrl+U shortcut, or right-click the page and click the “View page source” menu item.
- Search for
application/rss. If you find a<link>tag with atypeattribute ofapplication/rss+xml, then you’re on the right track!
You can try and search for application/atom+xml to find Atom files. There are some differences in the format, but they’ll work just fine for our purposes.
- Copy the URL in the
hrefattribute of thelinktag from the previous step.
In this exercise, I’ll use the link below for my RSS feed. For those of you who are interested in tech, this source may be familiar:
https://techcrunch.com/feed/
Try visiting this link yourself and see what you can find! Notice the XML, the names of the elements, and what’s inside. Now that we have a feed, let’s try out newsboat and see what we can do!
RSS and newsboat
newsboat is a command line RSS reader. I’ll leave installing the application as an exercise to the reader, but I’ll share some basic configuration details for including and organizing feeds.
Adding feeds
Since we have our URL for the feed we want, we can now add it to newsboat. By default, the configuration files are located in ~/.newsboat. To add a feed to newsboat, open the ~/.newsboat/urls file in a text editor of your choice, and add it to the file.
# Tech articles (you can add comments in here, too!)
https://techcrunch.com/feed/
Once saved, we can now run the newsboat command and check our feed. Here’s an image of our news feed at the moment.
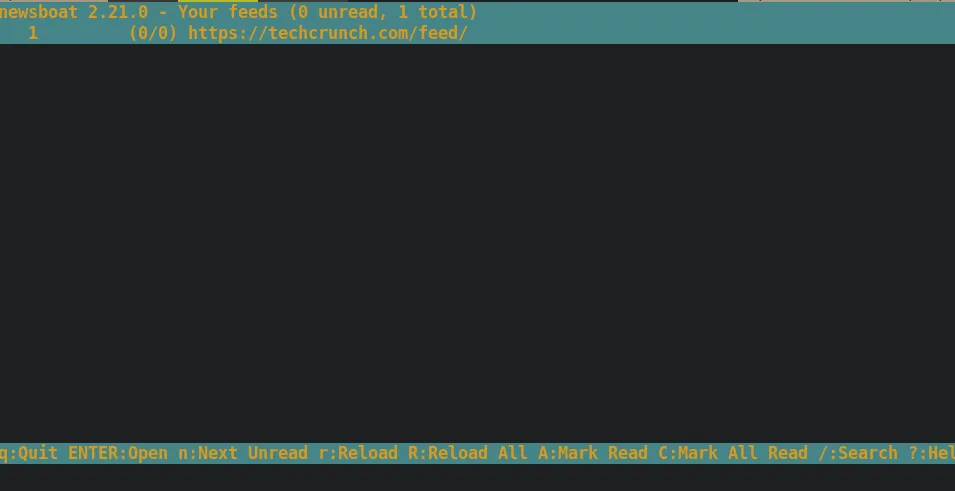
As you can tell, it’s pretty sparse. There are currently no articles in this feed. Also notice the commands at the bottom of the screen. This contains some hints on how to use newsboat, so don’t forget to read them!
Let’s try reloading this feed and see what happens. Press the r key, and notice the articles appear after a couple of moments.
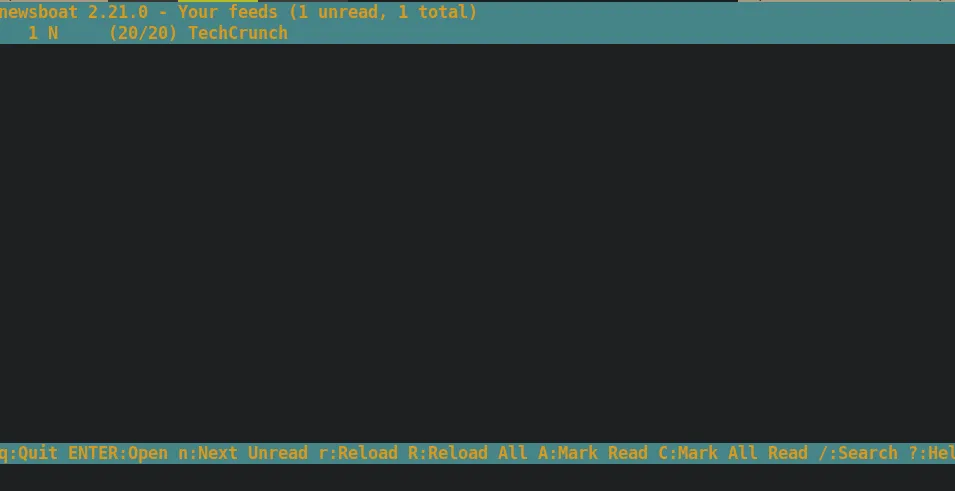
To enter the feed, press the Enter key. Now that we see a list of articles…
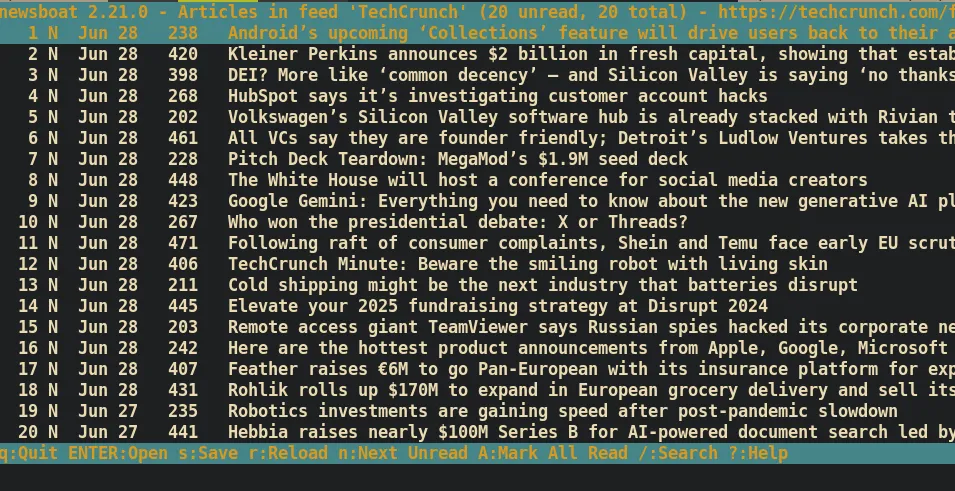
Pressing Enter again enters an article.
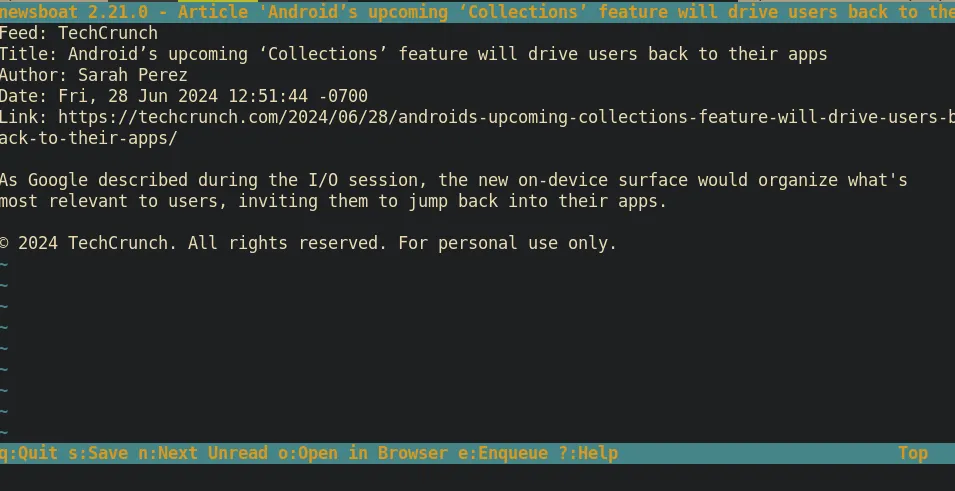
This opens a reader that controls similarly to less. You can page through content with Space and b, or scroll with the arrow keys. You can also search for terms by pressing /, followed by your query, and navigate forware and backwards through results with n and N, respectively.
However, the article as seen above can’t be the complete article, can it? You’d be right to think that, because this is only an excerpt of the article. This breadcrumb encourages readers to visit the article in a web browser, so let’s do so by pressing o and see what happens.
Unfortunately we’re now taken out of the text only interface, and into a graphical web browser. While some sites are more pleasant to read (like TechCrunch, admittedly), other sources may be more invasive than others.
How can we keep our news browsing to the terminal and only read text? Enter lynx.
HTML and lynx
Lynx is a terminal web browser. Like other web browsers, it can navigate to a web page with a URL, and render the HTML returned from the server. You can interact with links to navigate to other pages. The key difference is that lynx only renders text. This is perfect for reading the news without getting distracted by flashy graphics!
Again, I’ll leave installing lynx as an exercise to the reader. Rather than following the installation instructions, it may be easier to find it in whatever package manager and repository your system supports (i.e. brew for macOS, apt for Debian, and so on).
Here’s an example of what the home page looks like with lynx.
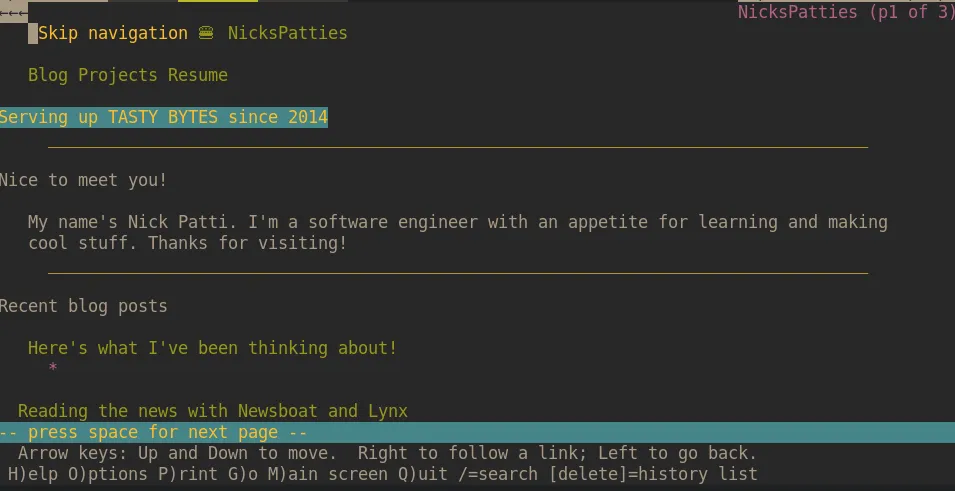
You may notice that active links, headings, and <hr> (horizontal rule) rendered on the page above. Other elements are rendered with their alternative text, like images.
Using a text based browser for better web development
lynx exposes semantically incorrect HTML by laying all the text content bare, making it easier to catch issues. I’ve found it useful to make sure images contain the appropriate alternative text.
I found this post by Terrence Eden informative, and presents a nice example of using lynx to analyze a web page.
Let’s take a look at the article from above with lynx using the following command:
lynx https://techcrunch.com/2024/06/28/androids-upcoming-collections-feature-will-drive-users-back-to-their-apps/
When prompted to save cookies, press the V key to never save them. They won’t enhance your reading experience. After a couple of moments, the page will load. Scroll down with Space (again, just like in less), and you’ll encounter the body of the article.
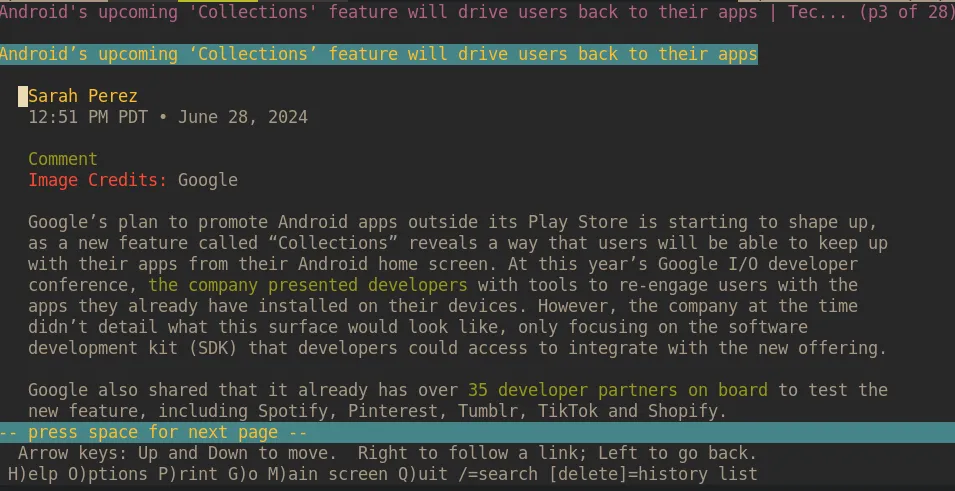
Interacting with the article in this way, I argue, is a pure experience designed for reading. The text, the only thing I care about, is rendered in a way that’s unobstructed and easy to see. I don’t have to select my cookie preferences or privacy settings. By using a browser that doesn’t support JavaScript by default, this concern is no longer a thought.
Now that we’ve installed and tried lynx out, let’s connect newsboat and lynx together for a seamless news reading experience.
Putting them together
Let’s configure newsboat to use lynx when opening an article in a web browser. Fortunately, the process is straightforward. Create a file called ~/.newsboat/config if it doesn’t exist, and add the following line.
browser lynx
Save the file, and then re-open newsboat. Try opening an article with the o command, and see what happens! Below is a video of the whole process from start to finish.

If your flow looks similar to the one above, then congratulations! You’re well on your way to a zen-like news reading experience!
I’ve started reading my news in this way, and anecdotally, I’ve read more news articles than I have before. Since I’ve curated my list of sources in my url file, I can find what I’m interested in faster than using a search engine.
There’s the added bonus of having less clutter in my email inbox! Now that I have my news in newsboat, I can unsubscribe from newsletters, and keep my email to actual correspondence instead of mixing the two together in my inbox. Everything is a little more organized thanks to this approach!
Some considerations
I’ll admit that this approach is not perfect. While this is a good starting point for a zen-like news reading experience, I had hiccups while trying this out.
Other CLI browsers?
There are additional applications I can try for reading articles. They may render HTML elements a little nicer, or have better controls that I’m used to. I’ll have to check out these other browsers to see if they work better for me:
Mismatch in controls between newsboat and lynx
Some controls between these two applications behave differently from one another. A common hiccup I encounter is using Ctrl+n in newsboat. In lynx, you can partially scroll down and up the page by using Ctrl+n and Ctrl+p, respectively. However, the n key in newsboat goes to the next unread article, even if Ctrl is pressed. This has gotten me mixed up a few times.
Perhaps there’s some keybindings I can set in newsboat to prevent this behavior from happening.
Viewing photos in newsboat
When viewing articles in newsboat, you may encounter a link to an image in an article. They may look like this:
[Image 1][1]
You can still open that link with your browser, but you’ll most likely run into an error if you’re using lynx; it won’t be able to render the photo.
A terrible, hacky solution is to change the browser to an application that can view photos. For instance, if you use feh as your image viewer, you can run the following command in newsboat.
:set browser feh
Then, open the link to the image as you would a normal web page. This will open the link with feh, and you’ll be able to see the image. Once you’re done, set the browser back to your browser of choice.
:set browser lynx
Where’s your RSS feed?
This exploration has reminded me of the importance of RSS, and as you may notice, my site doesn’t support it! That’s not good! I’ll add RSS support to the site as soon as possible. Thankfully, creating an RSS with Astro is well documented. Look for an update coming soon!
That’ll do it for now. Hopefully you learned something interesting, and I’ll see you all next time!