
Planning the ultimate Limp Bizkit experience with Playwright
Did you know that prolific nu-metal band Limp Bizkit invites fans on stage to perform with them? It’s true! Fans have sung, rapped, and played instruments live with them before. Limp Bizkit even assembled entire bands made of fans to perform, to varying degrees of success.
My friend and I want in. We’re planning on seeing Limp Bizkit next month, which gives us plenty of time to prepare. The question is, which song should we rehearse? And although it’s probably rare, what is the likelihood that Limp Bizkit will invite us on stage to perform with them?
Fortunately, there’s a resource that is the Wikipedia for live music called setlist.fm. This site contains over 8 million set lists, so if you’re interested in learning what your favorite artists like to play live, then this is a great resource.
With 104 pages worth of set lists at the time of writing, handling this data ourselves will take time. Generously, navigating to a set list and copying it to another document takes about 30 seconds. 10 set lists per page, and 104 pages put the total time of just moving the data elsewhere to 8 hours and 40 minutes.
This data needs to be obtained automatically to answer these questions and give ourselves the most time to rehearse. Fortunately, we can turn to Playwright and NodeJS to help! Once the data is in our hands, we can use some command line programs to organize our data, and some spreadsheet software to create some visualizations.
With all this information, we’ll be able to answer our questions: How likely will we be invited to play music with Limp Bizkit, and what songs should we rehearse?
The data scraper
If you’d like to read my code along with this post, you can view the lb-scraper code here! I’ll explain some key details about the scraping process below.
Initializing the browser
If you’re familiar with Playwright, you may have used it to write end-to-end tests, verifying your website behaves as expected when user interact with it. Your project may have had some sort of configuration file to define which browsers to use during testing to ensure cross-compatibility.
Since we’re only interested in accessing Limp Bizkit’s set lists through one browser, we don’t need this configuration. However, this means we’ll have to define our own page component. The page component requires a context to open, which in turn requires a browser.
Here’s me initializing the components required to open a web page with Playwright without the use of a test runner or configuration file.
import { chromium } from "playwright";
// ...
const browser = await chromium.launch();
const context = await browser.newContext();
const page = await context.newPage();
This code starts an instance of the Chromium browser. Then, it starts a new browser context. Think of a browser context like a specific user profile that has its own preferences, like what color scheme to use. “Incognito mode” is another example of a browser context. Finally, a new page is created from the context.
Once we have the page assigned, we’ll be ready to navigate to where we need to go!
Iterating through pages
It may make sense to take this link to Limp Bizkit’s setlist.fm page and plug it into the page.goto function. This’ll automatically navigate that Playwright page to the provided location.
await page.goto("https://www.setlist.fm/setlists/limp-bizkit-33d69c2d.html");
However, there’s a simpler option. If you’re looking at the Limp Bizkit set list page, try clicking on the pagination links underneath the sets lists, and look at the URL. There’s a query parameter called page in there!
Instead of having to locate the correct link to click to move to the next page (like you would in an e2e test), we can pass the set lists page index to the URL of our goto function! So the function becomes this instead:
await page.goto(
`https://www.setlist.fm/setlists/limp-bizkit-33d69c2d.html?page=${currPage}`,
);
So then how do we know what currPage is? We can find this easily by defining our start and end page indices. Additionally, I give the script user the option to define their own bounds with the -s and -e options. Here’s the code below.
const argsInput: string[] = [...process.argv].slice(2);
const args = {};
// ...
// iterate through the arguments
for (let i = 0; i < argsInput.length; i = i + 2) {
const name: string = argsInput[i];
const value: number = parseInt(argsInput[i + 1]);
if (!name.match("-[s|e]") || !value) {
console.error(`Error with arg ${name}, value ${value}`);
printUsage();
process.exit(1);
}
args[name] = value;
}
const startPage = args["-s"] || 1;
const endPage = args["-e"] || 105; // not inclusive
Notice how I’m skipping two arguments at a time in the loop above. I expect the flag and its value to appear next to each other in the argument list. If there are no values defined in the arguments, then we’ll start with page 1 up until page 105 by default.
We now have the code to iterate through all the pages of Limp Bizkit’s set lists. Let’s go one level deeper and find the links to each individual set list. We’ll use a locator to help us out.
Locating the set list data
Now that we know how to navigate to each page of Limp Bizkit’s set lists, we can navigate to an individual set list to the data we need. To do this, we’ll use locators. Playwright locators can represent an element or an array of elements on a web page. They contain built-in functions.
Although it’s poor form to use CSS selectors as locators in end-to-end tests according to Playwright, we can use them in our scraper to find all the <a> tags with the summary url class. These are the links to each individual set list where the song data is located.
const setLinks = await page.locator("a.summary.url").all();
I wanted to open a new page for each URL in this list to keep the search page and individual set list pages separated. Call me paranoid, but I wanted to ensure no mischief in the setLinkPage below will make me lose my progress.
for (const setLink of setLinks) {
const setLinkUrl: string | null = await setLink.getAttribute("href");
if (!setLinkUrl) {
continue;
}
// open a new page, since I don't want to lose my progress
const setLinkPage = await context.newPage();
// the href has a relative path, so we remove the `../` from it
await setLinkPage.goto(`https://www.setlist.fm/${setLinkUrl.slice(3)}`);
//...
}
The setLinkPage has the list of songs we want to copy. We’ll use another locator to find the individual songs that we’d like to record. If you’re looking at an individual set list page, you’ll notice there could be different types of songs: performed songs and tape recordings. The distinction is made clear in the HTML and CSS selectors, which can be seen by inspecting the page on a browser.
<!-- ... -->
<ol class="songsList">
<li class="setlistParts tape"><!-- Sweet Home Alabama --></li>
<li class="setlistParts song"><!-- Break Stuff --></li>
<!-- ... -->
</ol>
<!-- ... -->
Therefore, our locators to find the songs that Limp Bizkit performed at a given concert looks like this:
const songData = await setLinkPage.locator(".setlistParts.song").all();
Cool! We found the individual songs we were looking for! But what data specifically do we care about?
Grabbing the right data
It’s safe to say that the more data that is obtained, the easier it is to see patterns within that data.
Since my friend and I are trying to optimize our chances to perform with Limp Bizkit, we need to know at minimum:
- The name of the song that was performed
- The notes regarding the song performed
- The date when the song was performed
With this information, we should have a distinct list of performed songs and their corresponding notes, right? Not quite! There are some considerations to account for which will influence what data should be grabbed.
Encores
It’s possible a song is played more than once, and it’s also possible that one performance may not feature a guest, while another does. To distinguish between two performances of the same song, we can add another field to our data:
- The order in which the song is played in the set
This order variable also helps answer another related question: When within their set does Limp Bizkit like to invite a fan on stage to perform? This knowledge tells us when Limp Bizkit will start looking for fans to perform with them, and will dictate when we should make our move to the front of the stage.
Multiple performances during one day
Although highly unlikely, I wanted to make sure that my data would not get messed up if Limp Bizkit performed multiple shows in a single day. To do so, I also added this data to the collection.
- The name of the concert performed
This, along with the date and order, ensures individual song performances are unique enough that they are not accidentally double counted or filtered out when we try to sanitize the data. Later, we’ll find this information is useful for conducting additional research.
Writing the data
I decided to write the song data to a tsv, or tab-separated values file. This is the simplest way to delimit fields. This helper function creates a row of data in stdout.
const writeRow = (data: string[]) => {
process.stdout.write(data.join("\t") + "\n");
};
// write the headers to stdout
writeRow(["Order", "Song", "Info", "Concert", "Date"]);
Recall that we located all the songs on a set list page with the following code:
const songData = await setLinkPage.locator(".setlistParts.song").all();
When we iterate through each song, we can grab each column of data with the following code:
let order = 1;
for (const songDatum of songData) {
const song = await songDatum.locator(".songPart").innerText();
const info = await songDatum.locator(".infoPart").innerText();
const concert = linkContent;
const row = [order + "", song, info, concert, date];
writeRow(row);
order++;
}
Writing to our file is done via the command line. We can direct the output of the script to our data file.
node . >> data.tsv
Running this script for all pages takes some time, so feel free to take a break if you’re following along. It’ll take about 15 minutes for the process to complete, give or take.
At this point, we can now run our script and save the file for further review. The script creates a tsv file containing all the songs performed by Limp Bizkit at each of their concerts, along with notes about special cases, like fan performances.
Command line data manipulation
Given our data.tsv file, we can use some built-in command line applications to sanitize our data, and filter it out into different categories as needed.
sort
First, we’ll remove any duplicate rows from the data with the sort command. Duplicates may appear if the script was run more than once on the same set list pages.
sort -u data.tsv >> data-uniq.tsv
-umeans only unique lines in the file will be shown
wc
How many songs in total did Limp Bizkit perform? We can find this out by using the wc command.
wc -l data.tsv
9909 data.tsv
-lmeans return the number of lines in the given files.
Since each line represents a song performance, then the total count is an impressive 9909 songs performed to a live audience.
wc can also be used to verify if our previous sort command filtered out any data or not.
wc -l data.tsv data-uniq.tsv
9909 data.tsv
9909 data-uniq.tsv
19818 total
In this case, sort didn’t filter anything out, so our data looks OK to use.
cut
cut can be used to obtain data from a specific column. By default, cut can process tsv files without any additional parameters.
How many concerts did Limp Bizkit play in their lifetime? We can find out using a combination of the above commands!
cut --fields=4 data.tsv | sort -u | wc -l
635
--fields=4tellscutto only get the 4th column from this dataset. This argument can accept single columns, multiple columns (--fields=1,3), or a range of columns (--fields=1-3).
Notice that we’re piping the output from each command and using it as the input of the next. First, we grab the concert name column from the data.tsv file. Then, we filter out repeated lines with sort -u. Finally, we count with lines of output with wc -l, which gives us our final answer of 635.
grep
This command may be the most familiar to command line enthusiasts. grep is used to find instances of a search query within a file. How many times did Limp Bizkit perform with fans on stage? We can find out by using grep like so.
grep --extended-regexp "(fan|audience|guest)" data.tsv | wc -l
119
How accurate is this filtering?
Pretty accurate, but there are some edge cases. Consider these two entries.
| Order | Song | Info |
|---|---|---|
| 9 | Pollution | (With a fan) |
| 9 | Dad Vibes | (With 2 fans on stage only taking selfies/videos) |
The first entry has the info “With a fan.” This could mean “with a fan on stage dancing”, or “with a fan performing alongside the band.” The level of the fan’s involvement is not clear, so in those cases, I like to find some evidence of what the fan did, typically via videos on social media.
The second entry is more clear; they were not performing alongside the band, and were only present on stage. This is enough to reveal a downfall of my filtering technique, however. I may have entries that I don’t care about.
This is enough information to start estimating the likelihood we can perform with Limp Bizkit live. If we divide the number of songs fans performed with the number of songs they played in total, we get this:
119 songs performed with fans / 9909 total songs performed = 0.012 = 1.2%
This is a little bit discouraging. Note that this does not even filter out the fan performances with specifically fan performances with instruments.
grep --extended-regexp "(fan|audience|guest)" data.tsv | grep --extended-regex "(guitar|bass|band|instrument)" | wc -l
15
15 songs performed with fans on instruments / 9909 total songs performed = 0.0015 = 0.15%
Even without careful calculations, the numbers are staggeringly low. Assuming that everything goes according to plan, a less than one percent chance of success is enough to not even try.
But as people who know me may understand, I’m not so easily deterred.
Looking at the data another way
The analysis from above does not provide the entire picture. There are some other questions I would like to ask. For instance, has Limp Bizkit been performing with fans more often in recent years? Are there specific songs that are more likely to be selected? Are there techniques we can use to increase the likelihood of us getting selected to perform?
Limp Bizkit is open to fans performing on stage. Perhaps the low numbers don’t represent their willingness or opportunity to let fans on, but the drive of the fans to perform themselves.
In my Limp Bizkit scraper repository, I added a spreadsheet document where I’ve been doing some analysis. I’ll share a couple of the things I did within the sheet.
Finding video evidence
As I was working with the data, I was searching for video evidence of guests performing with Limp Bizkit to double-check some of the filtered results from above. As such, I added a “Video URL” column.
Finding the data was simple with what I already had. Videos usually have the name of the song performed, the date, and the name of the concert in their titles. These videos I found included some fun information about these interactions, including these fun tidbits:
- Fred had a clone of himself perform with him one time in Vegas!
- During a 2023 performance in Germany, Fred was under the weather, but some legendary fans stepped up to keep the show going! (1, 2, 3)
- Some fans in Argentina got on stage and almost messed up Fred’s entrance. Diplomatically, he shares “I like those guys, but they were very boring.”
Most importantly, these videos verify whether a fan performance actually takes place, which can impact what songs my friend and I should prioritize learning. If fans have a tendency to only get up on stage and dance to a given song, that decreases the likelihood Limp Bizkit will allow having fans play that song.
Having a choice in song?
Speaking of the band letting fans play songs, I discovered through those videos that fans were sometimes given a choice of song to play. If fans were lucky enough to be invited on stage, one of three things happen:
- Limp Bizkit assigns a song for them to play (“You have to be able to play Hot Dog.“)
- The fan chooses what song they want to play, and the band accepts their choice. (“What’s he going to play?“)
- The fan chooses what song they want to play, but the band refuses their choice. (“What do you want? … No ‘Break Stuff’ tonight.“)
Fortunately, the numbers show that a majority of the time fans are let on stage, they have the choice of what song to play. Of the 16 times fans were invited to play instruments on stage with the band, fans got to choose which song to play 12 times. In short, 75% of the time fans were invited on stage, they had a choice of song.
Signs
If you previewed the videos linked above, you may have noticed that some fans that were invited on stage had signs.
- A little fan had a sign asking if he could “Break Stuff” with Fred.
- A fan held a sign and grabbed Fred’s attention in Germany.
My findings revealed that if we had signs, and all other factors went in our favor, we would have a 100% chance of being invited up. More clearly, having a sign always increases our chances of being picked to play. Such an advantage cannot be overlooked, so creating signs showing that we want to play is essential.
Order and timing
Since we grabbed the order that each song was played, we can estimate when we should make our way to the front of the stage, or at the very least, how much time we have to position ourselves in the most advantageous way.
After counting the total songs in each concert for each song that was performed with fans on instruments, I had the data at my disposal to calculate at what portion of the concert the song took place. Calculating the timing ratio of each song played leads to this graph.
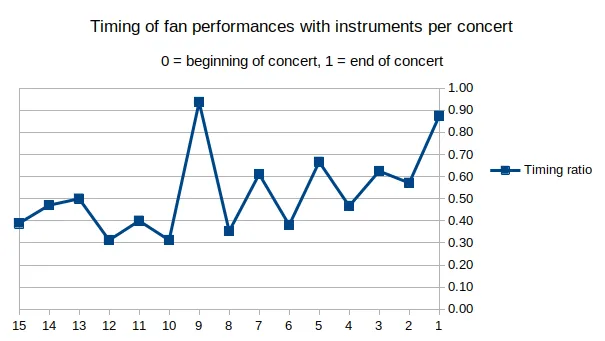
On average, fans with instruments performed about halfway through the concert. Given that the average number of songs played in 2024 is 12, we’ll need to start positioning ourselves in the crowd by the time 5 songs have played. This should give us plenty of time to make our way to the front.
Conclusion
Although this data was extremely discouraging at first, it was very useful for finding additional information about the times fans did perform with the band. Manipulating and adding more information has given my friend and me some strategies we wouldn’t have found otherwise. To maximize those changes to play with Limp Bizkit during their show, my friend and I will do the following:
- Prepare multiple songs to play, in case our first choice is not available
- Create an eye-catching sign, sharing our intent to play with the band
- Get to the front of the crowd with our signs ready by the time the concert is half-way done
This begs the question, which songs should we pick to perform? We’ll refer to this chart below for the answer.
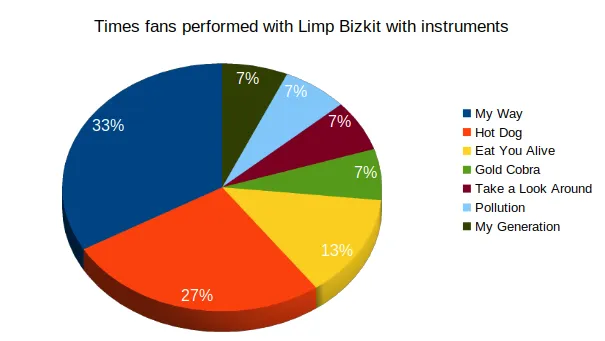
The majority of times that the stars align for these lucky fans, they’ll play either My Way or Hot Dog. These are our second and third choice of song. So then what’s our first choice?
9 Teen 90 Nine, specifically to chug on this riff here.
Future improvements?
Although Playwright, command line tools, and spreadsheets have gotten me this far, there are some things I would like to consider if I were to make this again.
Improving scraping speed
Running Playwright takes time. When running in headless mode, an entire browser runs in the background, rendering the output of the HTML, CSS, and JavaScript, which takes a couple seconds.
Now, consider this command, which obtains a specific set list and searches for the same song items as the locator in my Playwright script.
curl https://www.setlist.fm/setlist/limp-bizkit/2024/megaland-landgraaf-netherlands-3babf870.html | grep --after-context=3 "setlistParts song"
We can find the same data required for our analysis in a fraction of the time. This is possible since the data we’re looking for is included in the HTML document from setlist.fm; there’s no need to wait for JavaScript to request and load data separate from the document!
If we can take advantage of this, then we can finish scraping data much faster than with Playwright! This could make repeat runs more efficient. The only thing that’s missing is a DOM parser to simplify development.
Replace spreadsheets with a database
I’ll admit, adding the data to a spreadsheet seemed like the easiest solution. However, many of the things I was trying to do in the spreadsheet can be accomplished with a database with a robust querying language. Using a spreadsheet was straightforward since I had more control to quickly add, remove, and organize data via columns.
However, using an actual database will be easier to perform certain tasks, like verifying that entries are unique, or fetching data that meets certain conditions. Additionally, I wouldn’t need to rely on command line tools to filter and sort data.
For data visualization, instead of using a spreadsheet with extremely clunky cart generation, a data visualization library like D3 can be used to create interactive graphs and charts instead.
Thanks for reading!
This has been a fun project, and I hope you enjoyed reading. I’m off to write more code and practice some more riffs. Stay tuned for more updates! I’ll also let you all know if my strategy is successful. ;)